DSP 学习笔记 |(五)HiFi 4 User's Guide 笔记
Last updated on April 30, 2023 am
本文笔记整理摘自《HiFi4 DSP User’s Guide》。
先导阅读手册:

一、 HiFi 4 概述
- Cadence HiFi :Cadence Tensilica HiFi DSP 架构,用于音频解码
- Tensilica:嵌入式处理器公司,已被芯片 EDA 巨头 Cadence 收购
- Xtensa:DSP 处理器核心,也是该系列的型号名称,也是该处理器中指令集架构的名称
- HiFi:特指 32 位音频/语音处理数字信号处理 (DSP) 核,基于 Xtensa® 架构
1.1 HiFi 4 特点
HiFi 4 DSP 是一个高性能的嵌入式数字信号处理器,专门为音频和语音处理进行了优化。
HiFi 4 DSP 由三个主要部件组成:
- 一个 DSP 子系统;
- 一个可选的单精度浮点单元;
- 一个协助比特流访问和变长(Huffman)编解码的子系统。
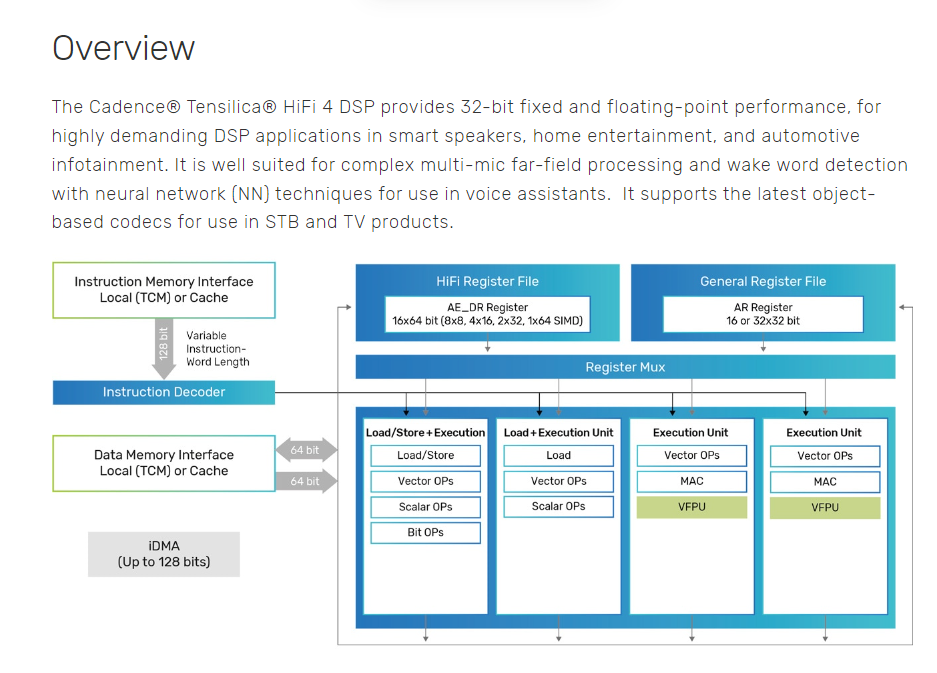
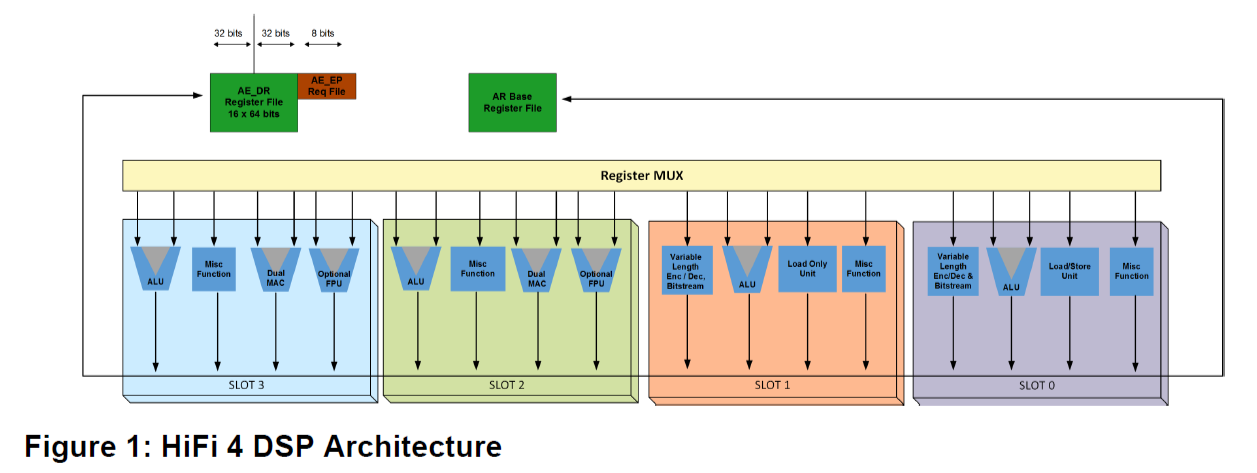
- HiFi 4 DSP 是一个 VLIW 架构,支持并行执行四个操作。
- DSP 的读取、比特流和 Huffman 操作以及核心操作都可以在 VLIW 指令的 0 槽和 1 中,存储仅在槽 0 中可用。DSP MAC、ALU 和可选的浮点操作通常在槽 2 和槽 3 中进行。
- HiFi 4 DSP 是建立在 Xtensa RISC 架构的基础上,它实现了丰富的通用标量指令集,为高效的嵌入式处理进行了优化。
- 由 Cadence 提供的音频包不使用 DMA。因此,大多数客户要么使用缓存,要么使本地存储器足够大以覆盖所需的应用。
1.2 寄存器
AE_DR 寄存器
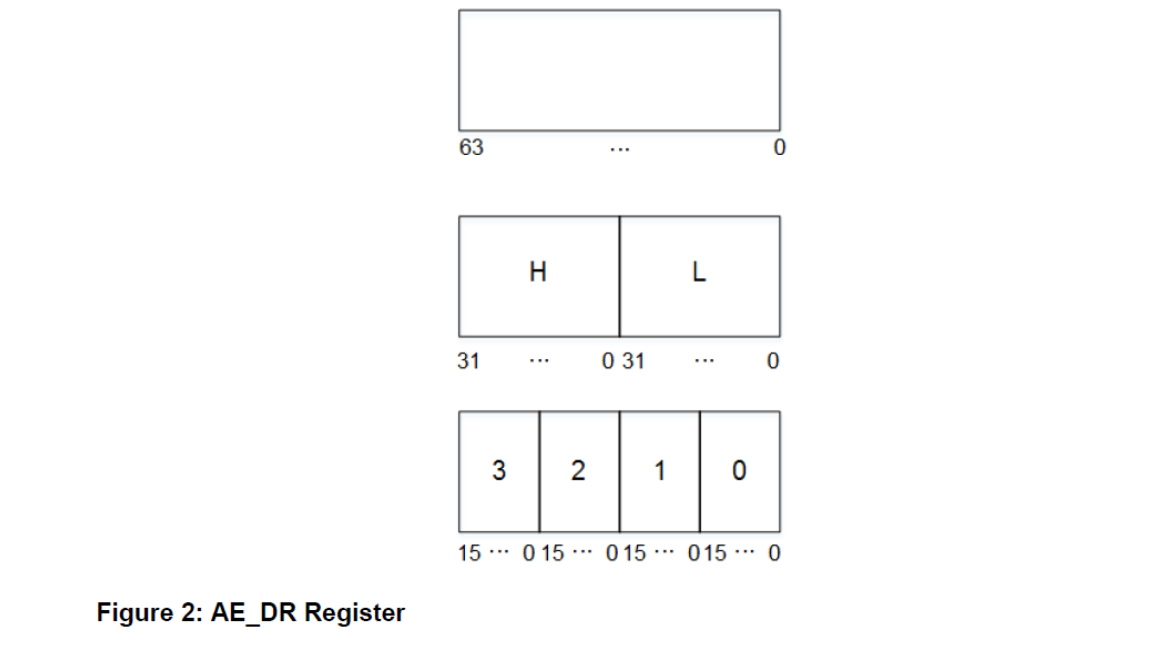
HiFi 4 DSP 包含一个 16 进制 64 位寄存器 AE _ DR。
当寄存器被存储到内存中时,寄存器的较高一半总是存储在较低的内存地址中,并从较低的内存地址加载。寄存器的单独的一半或四分之一始终是单独的数据项。 例如,如果将 32 位元素向左移动,则 L 元素不会溢出到高位元素中
AE_EP 寄存器
- HiFi 4 DSP 支持一个 4 进制、8 位的额外精度寄存器 AE_EP。
- 该寄存器的访问时间比 AE_D R寄存器晚一个周期。
AE_VALIGN 寄存器
- HiFi 4 DSP 支持一个 4 进制、64 位的对齐寄存器 AE_VALIGN。
- 使用这个寄存器允许硬件以每周期 64 位的速度加载或存储非 64 位对齐的 SIMD 流位/周期。
- 对齐的加载和存储只存在于槽0中,所以不可能同时发出这些指令。
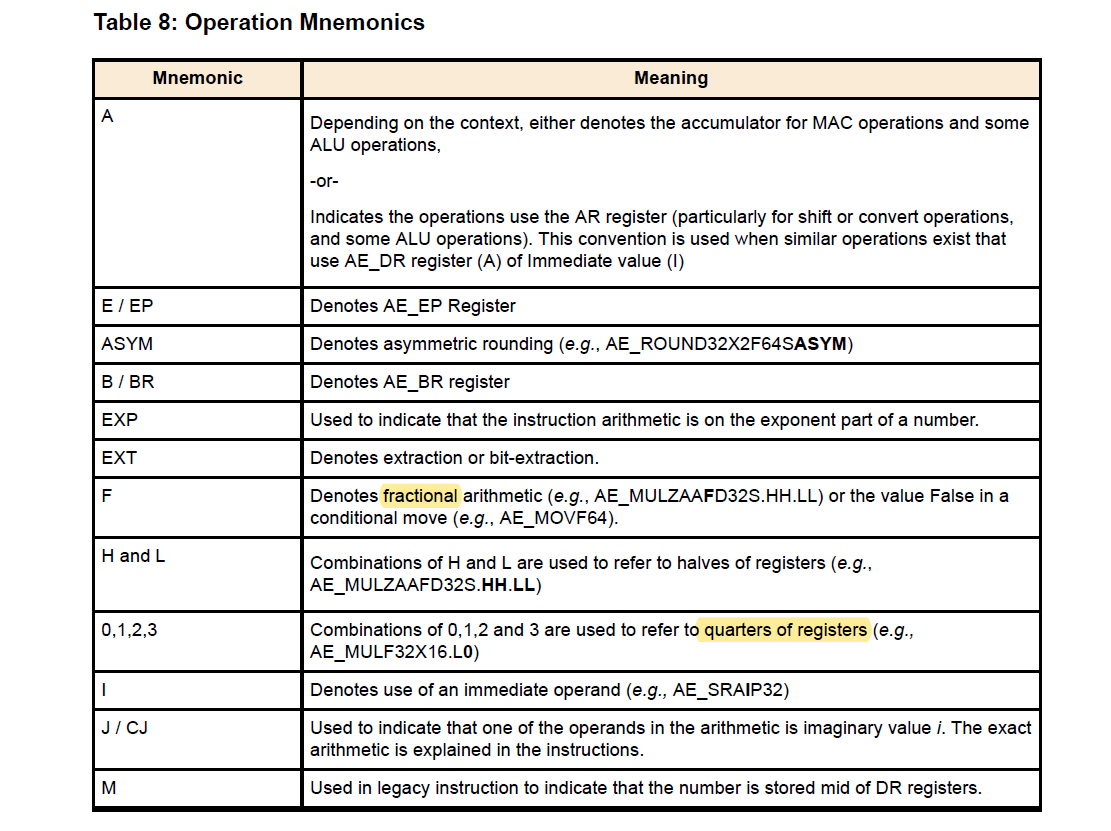
1.3 操作助记符
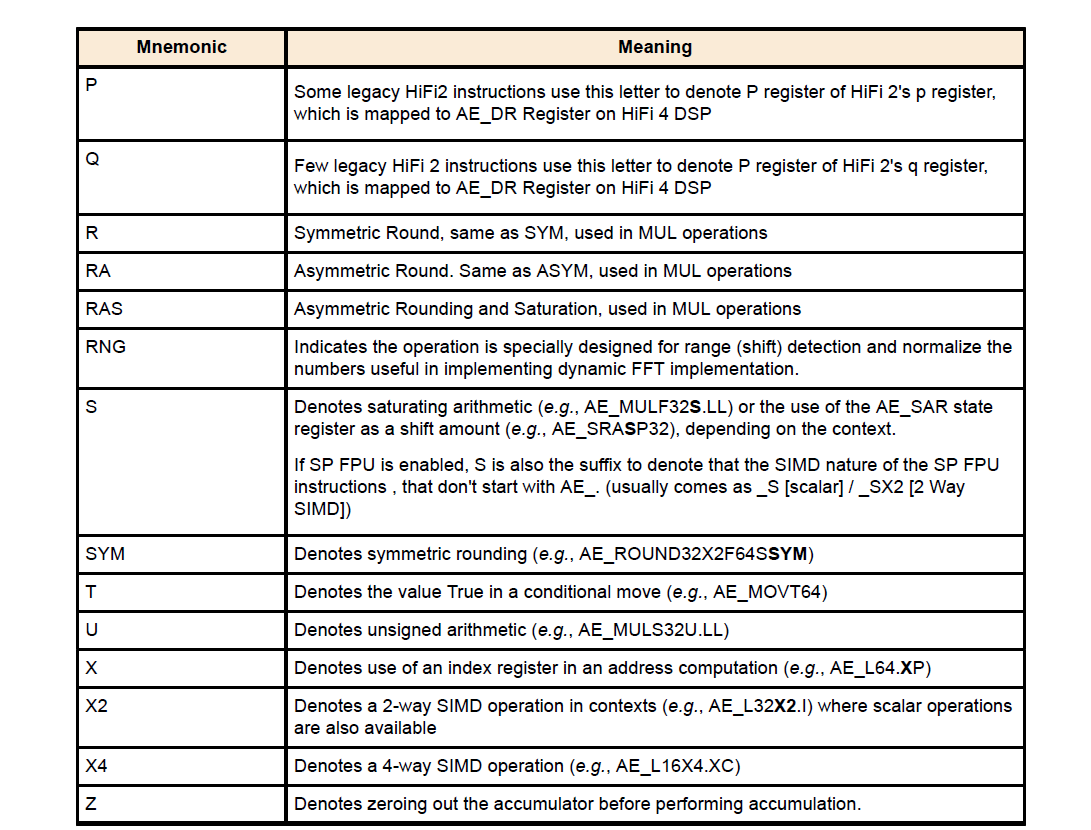
1.4 定点数及其运算
一个定点数的数据类型 m.n 包含一个符号位,在小数点的左边有m-1位,在小数点的右边有n位。
当表示为一个二进制的时候,最不重要的 n 位是小数部分,最重要的 m 位是整数部分。
1.5 VLIW 槽及格式
HiFi 4 DSP 可以在一个 88 位的指令束中发出 4 个操作,或在一个 48 位的指令束中发出 2 个操作。使用 Xtensa LX FLIX (VLIW) 技术,HiFi 4 DSP 支持几种不同的格式,有不同的插槽限制。每条指令都属于一种格式,但不同的格式可以在一条指令中打包不同数量的操作。
- 第一个插槽支持标量与矢量的 读取与写入,以及 标量 Xtensa 操作;
- 第二个插槽支持标量与矢量的 读取与写入,以及 矢量 Xtensa 操作;
- 最后两个插槽主要支持 矢量逻辑运算 与 矢量乘法运算。
对于可选择的浮点单元来说,大多数浮点操作都可在 slot 3 和 slot 4 中进行。
在优化 HiFi 4 DSP 代码中理解开槽的概念是十分重要的。循环通常受到只能进入一个或另一个槽的操作的限制。例如,每个周期不可能发出一个以上的(可能的SIMD)存储。如果一个循环被一个槽中的操作所限制,那么试图优化另一个槽中的操作就没有意义了。
二、DSP 编程
- HiFi 4 DSP 每个周期提供四个 MAC。 它提供对整数和小数运算的等效支持。
- 不利用 SIMD 的应用程序的运行速度将比利用 SIMD 的应用程序慢 4 倍。
- 对于 24 位和 32x16 位的应用程序,编译器不会自动矢量化。应用程序编写器必须使用显示矢量数据类型或内部函数来编写代码。
2.1 数据类型
- HiFi 4 DSP 支持 16、24、32 以及 64 位的数据类型。所有类型都包含整数与分数版本。

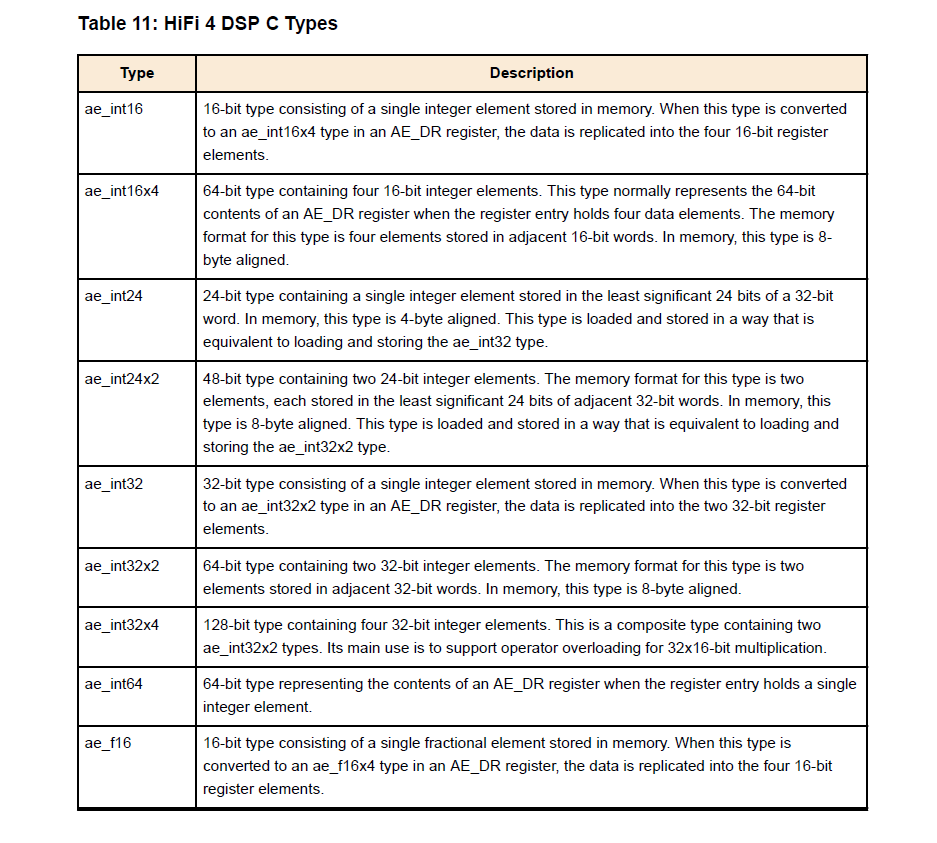
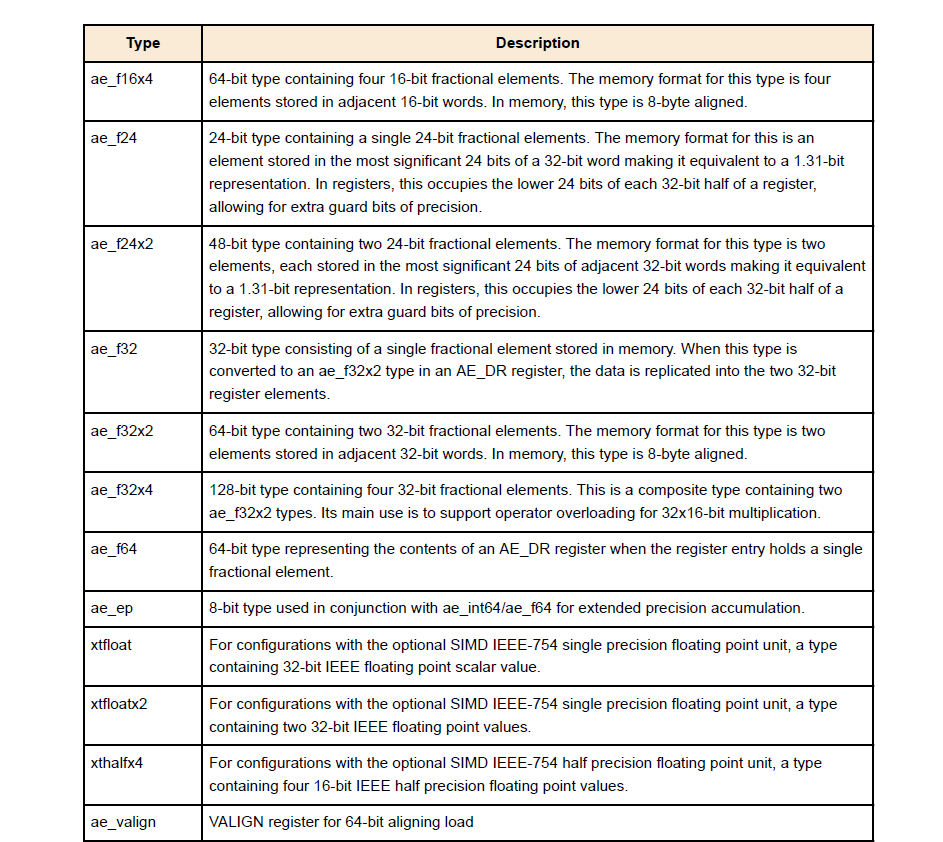

2.2 编码与解码

2.3 基于内嵌函数编程
每条 HiFi 4 DSP 指令都可以通过一个相同名称的内部函数直接访问,除了 “.” 需要全部变成 “_”。
三、HiFi 4 指令集
对于矢量读取和写入,内存中的高位地址总是存储在寄存器中的最小有效位。
HiFi 4 DSP 还支持两个圆形缓冲区,可用于对齐或不对齐的数据。
虽然向量变量不需要被对齐到 64位,但它们仍然必须根据每个标量元素的要求进行对齐,例如32位的向量的 ints。
AE_LA64.PP 是一个特殊的初始化指令,这条指令将数据从数据流的起点加载到对齐寄存器中。对齐指令工作的具体细节与程序员无关。只要调用 AE_LA64_PP 引导内在的第一个要加载的地址(不管是否对齐),然后用适当的对齐加载继续加载。
大多数读取和写入操作的助记符包含一个尺寸,表示操作符的大小;
大多数加载和存储操作的助记符包含一个后缀,表示如何计算有效地址以及是否更新基址寄存器。
定点数 1.31, 是指令里面操作的数据类型,int 之后,还有按照指令规范的类型来转换。
int = 2, 在经过 1.31 后,二进制,000….10(32位)。如果是负数,第一位是符号位,补码形式。

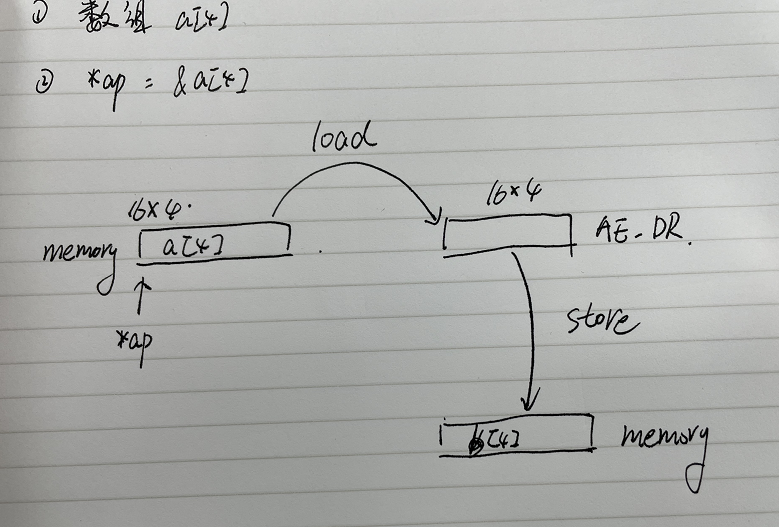
3.1 读取与写入操作
load 是将内存里面的值读取到寄存器(CPU 内部的存储单元)。如果都是放在寄存器的,寄存器哪有那么多地方给你存东西?
store 是将寄存器里面的值写入到内存。
1 | |
3.2 乘积累加操作
乘积累加运算 ( 英语:Multiply Accumulate, MAC,)。
乘法 multiplication、加法 adder、周期 cycle 就是 mac,乘加器,表示一个周期完成一次乘法和加法运算。DSP 的重要性能指标。DSP 的主要工作就是大量的乘加器运算。
DSP 一个机器指令周期能实现乘加运算,这是 DSP 的精髓。 实现这个运算的内核就是 MAC。



MAC:
两个和四个 MAC 操作有两种形式——双 MAC 取两个 MAC 的结果,并将它们加或减,如下示例所示。
1 | |
MACs:
SIMD MACs 不结合不同乘数的结果。相反,它们对数据的不同部分执行示例乘法操作,如下示例所示。
1 | |
高位和低位各算各的,SIMD MACs 将其结果打包为 32 位或 16 位,因此在其名称中使用 P。通过同时添加或减去两个乘法结果,双 MAC 指令能够保持它们的累积精度,而不需要写入多个输出寄存器。
- 在单乘法和 SIMD 乘法运算中,每个乘法/累加操作系列都有一个仅乘法变体,即乘法/加法变体和乘法/减法变体,通过将 accum_type 设置为空、A 或 S 来表示分别。
- 使用 MUL 变体,累加器内容会被以下结果覆盖乘法。 使用 MULA 变体,乘法的结果被添加到累加器内容并写回累加器。 使用 MULS 变体,结果从累加器的内容中减去乘法的值并写回累加器。
- accum_type 以 Z 开头的双 MAC 操作是对零进行累加的。换句话说,累积器的初始内容被丢弃。那些没有 Z的操作则是针对累加器的初始内容进行累加。在可选的 Z 后面,有两个字母表示加法或减法,两个乘法结果各一个。
- 小数乘法指令在 accum_type 后面有一个 F。
对称 & 非对称四舍五入
- 整数 SIMD 乘法指令扔掉了其结果的高位,就像标准的 C/C++乘法。小数 SIMD 乘法指令使用对称或不对称的四舍五入方法,将低位舍去。
- 在非对称四舍五入的情况下,两半被向上舍入,即 0.5 倍的最小有效结果位被舍入为 1.0,-0.5 倍的最小有效结果位被舍入为 1.0。即 0.5 倍的最小有效结果位被向上舍入为 1.0,-0.5 倍的最小有效结果位被向上舍入为 0。
- 在对称四舍五入的情况下,两个半数从零开始四舍五入,即 -0.5 倍的最小有效结果位四舍五入到 -1.0。
- 在指令描述中,对称舍入被称为 round,而非对称舍入被称为 round+∞。
饱和 & 非饱和乘法
执行操作时,某个中间变量的值的范围大于了最终结果的值的类型范围。
1 | |
- 没有保护位的小数 MAC 运算,1.31x1.31 到 1.63 或 1.31,1.31x1.15 到 1.31 和 1.15x1.15 到 1.15 或 1.31,使它们的结果饱和。 所有其他 MAC 操作都是完整的或具有保护位且不会饱和。
- 饱和乘法有一个 S 跟在大小或四舍五入的名称后面。
- 一些 16x16 位乘法器被设计为与 ITU-T/ETSI 内在函数,因此串联进行多次饱和。 这些指令的名称中有 SS。
其他
- 无符号乘以无符号的乘法,在其前面有一个 U。无符号乘以有符号 的乘法,在指定符前有一个 US。利用 AE_EP 寄存器文件产生 72 位累加器的乘法运算,在指令前有一个 EP。
- 所有 MAC 操作都出现在第三个或第四个插槽中。 出现在第三个插槽中的任何乘法运算都将具有后缀 _S2。 C/C++ 程序员可以忽略后缀。 编译器会在需要时自动将普通乘法转换为 _S2 乘法。
3.3 加、减与比较操作
Add, Subtract and Compare Operations

3.4 移位操作
Shift Operations 移位操作
所有移位操作都以前缀 AE_S 开始。下面的字母是 L 或 R,表示主要移位方向是左还是右。下一个字母是 L或 A,表示是逻辑移位(在右移时填入0)还是算术移位(在右移时符号扩展)。下一个字母 I 表示立即移位,A 表示 AR 移位,S 表示 AE_SAR 移位。后面是一个数字,表示被移位的元素的大小,还有一个可选的R表示右移位而不是截断的右移,以及一个可选的 S 表示饱和的左移。
3.5 归一化操作
3.6 Divide Step 操作
3.7 截断操作
Truncate Operations
AE_TRUNC16X4F32 Operation
3.8 移动操作

四、 HiFi 4 备忘录
4.1 HiFi 4 的头文件
1 | |