DSP 学习笔记 |(四)Xtensa ISA 笔记
Last updated on May 20, 2023 pm
本文笔记主要整理摘自《Xtensa® Instruction Set Architecture (ISA)》。
一、 XCC 编译器




二、 Candence 处理器




三、 语法
3.1 数据类型
ae_int32x2
由两个 32 位的数据类型组成一个 64 位的数据,8 字节对齐。如果使用 int 类型强制转换,那么在内存分布上,将是两个相同的 32 位数据,举例如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26void test()
{
int mem1 = 0x1234;
int mem2 = 0x5678;
ae_int32x2 p = mem1;
int *p1 = (int *)&p;
printf("(int)p = 0x%0x\n",(int)p);
printf("*(p1) = 0x%0x\n",*(p1));
printf("*(p1+1) = 0x%0x\n",*(p1+1));
ae_int32x2 p2 = AE_MOVDA32X2(mem1, mem2);
int *p3 = (int *)&p2;
printf("p3=0x%0x,*(p3) = 0x%0x\n",p3,*(p3));
printf("p3+1=0x%0x,*(p3+1) = 0x%0x\n",p3+1,*(p3+1));
}
输出:
(int)p = 0x1234
*(p1) = 0x1234
*(p1+1) = 0x1234
p3=0x2ffffeb8,*(p3) = 0x1234
p3+1=0x2ffffebc,*(p3+1) = 0x5678
分析:AE_MOVDA32X2作用是将两个32位数拼成一个64位数。
四、 基础的 SIMD 编程
SIMD :Single Instruction Multiple Data,单指令流多数据流,是一种采用一个控制器来控制多个处理器,同时对一组数据(又称“数据向量”)中的每一个分别执行相同的操作从而实现空间上的并行性的技术。在 微处理器 中,单指令流多数据流技术则是一个 控制器 控制多个平行的 处理微元.
由于单指令流多数据流处理效率高的原因,常被用于在多媒体应用中的 3D 图像和音视频处理。

基本的 SIMD 操作概念:
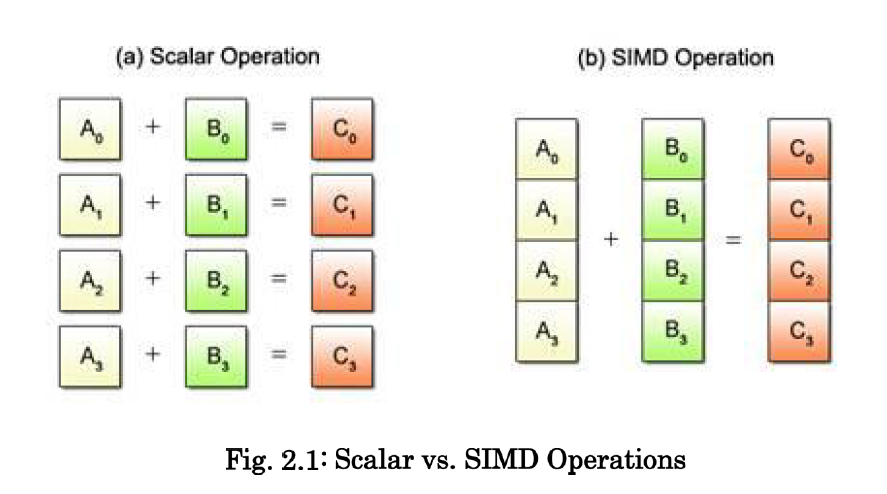
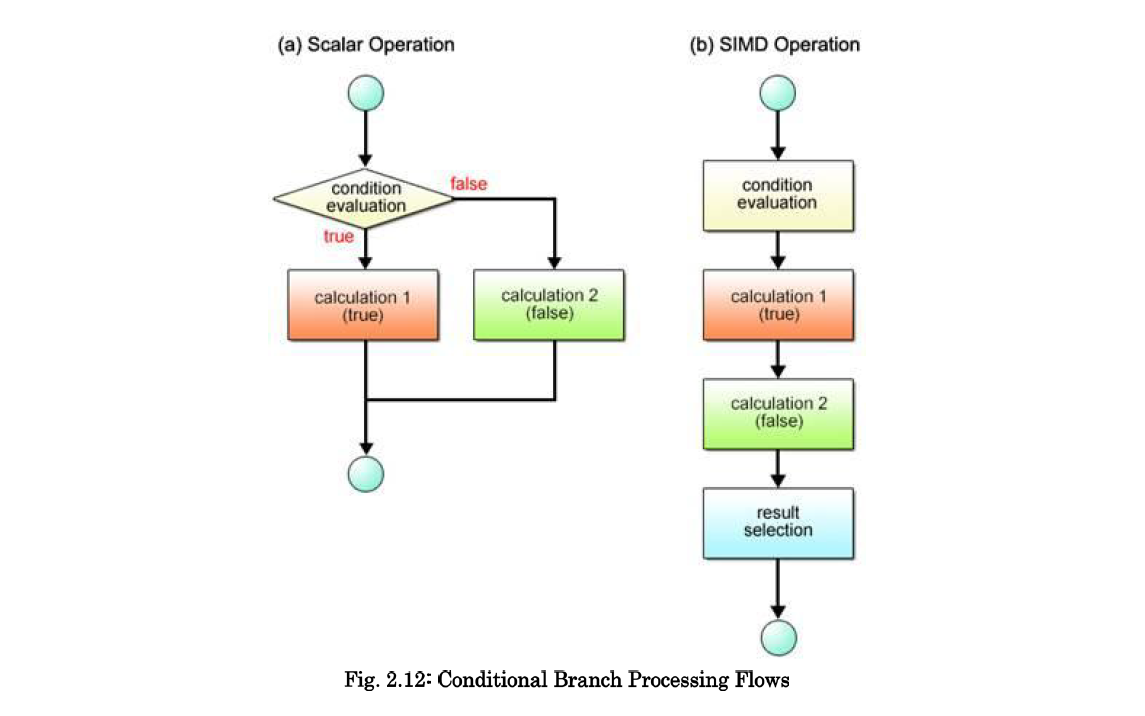
SIMD 操纵不能以不同的形式处理多数据,如下图所示。

4.1 矢量类型
C 语言常用的数据类型例如 char 、float 被称为标量类型。在 SIMD 运算中的数据类型被称作矢量类型。每个矢量类型都有其相应的标量类型。

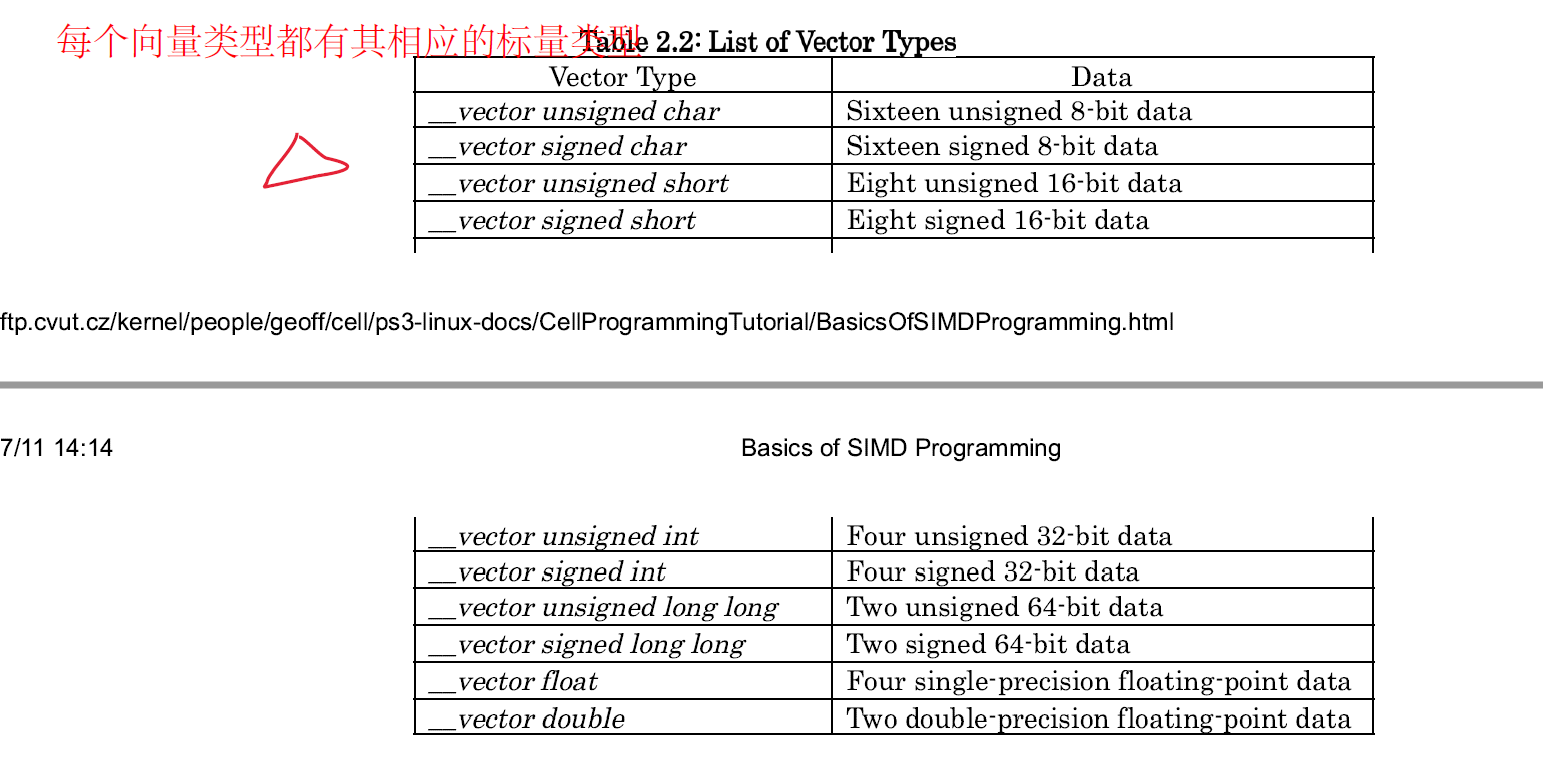
在 SIMD 编程中,经常需要将特定的向量元素称为标量或将标量块称为单个向量。本节介绍了满足这一需求的引用方法,例如,只输出向量的第三个元素或将标量数组输入数据捆绑成适合 SIMD 处理的向量成为可能。
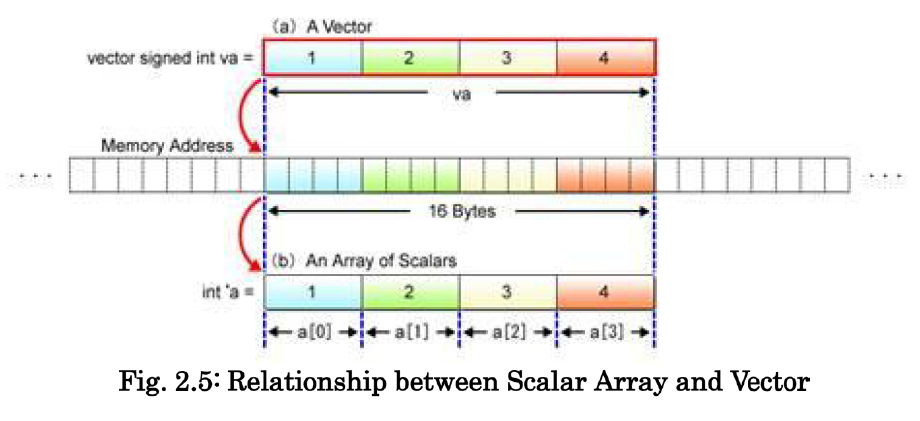
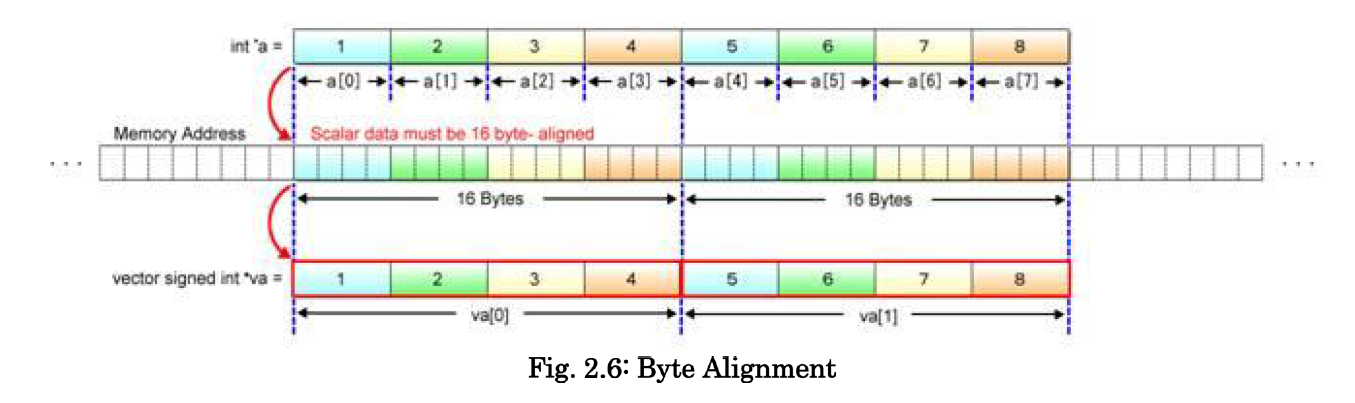
4.2 基础的 SIMD 运算
以加法为例,介绍标量运算与 SIMD 运算
a. 标量运算

b. SIMD 运算



c. 完整的加法例程 

运算几乎都是以标量矩阵作为输入数据。

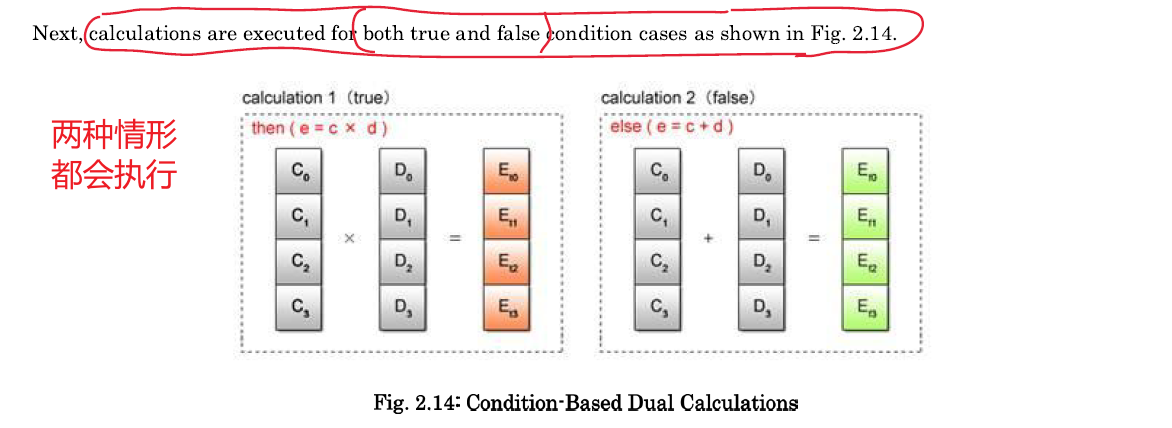
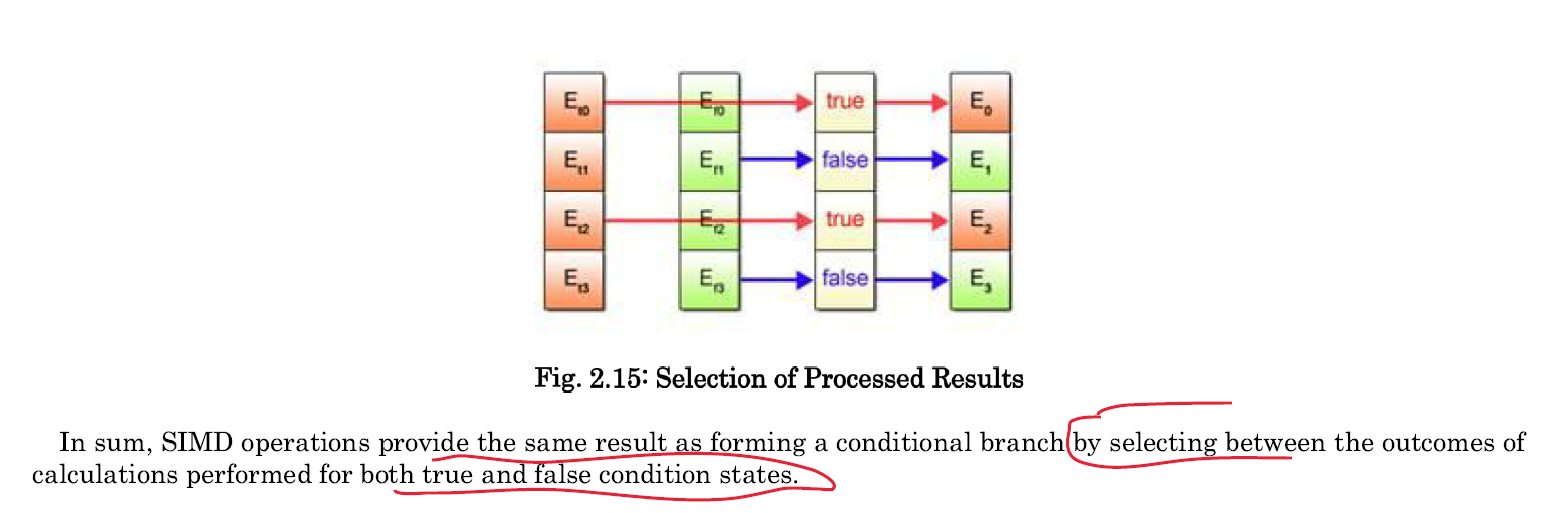
- 条件运算




五、寄存器

5.1 通用(AR) 寄存器
地址寄存器(Address Registers, AR)。每条指令最多包含三个 4 位的通用寄存器(AR)指令,每个指令可以选择 16 个 32 位寄存器中的一个。这些通用寄存器被命名为地址寄存器,以区别于协处理器寄存器,后者在许多系统中可能作为 “数据 “寄存器使用。然而,AR 寄存器并不限于保存地址,它们也可以保存数据。
如果配置了窗口寄存器选项,地址寄存器文件将被扩展,并使用从虚拟到物理寄存器的映射。
地址寄存器文件的内容在复位后是未定义的。
5.2 移位和移位量寄存器(SAR)寄存器
移位和移位量寄存器(Shifts and the Shift Amount Register,SAR)。ISA 提供了传统的即时移位(逻辑左移、逻辑右移和算术右移),但是它没有提供单指令移位,其中移位量是一个寄存器操作数。从一个普通的寄存器中获取移位量会产生一个关键的时序路径。另外,简单的移位不能有效地扩展到更大的宽度。漏斗式移位(两个数据值在输入移位器的时候被 catenated)解决了这个问题,但是需要太多的操作数。ISA 通过提供一个漏斗移位来解决这两个问题,其中移位量是从 SAR 寄存器中获取的。可变移位由编译器合成,使用指令从一般寄存器中的移位量计算 SAR,然后再进行漏斗移位。