DSP 学习笔记 |(二) 指令集架构
Last updated on April 30, 2023 am
本文将介绍指令集(ISA)概念,以便在后续的学习中建立其理论基础。
一、什么是指令集?
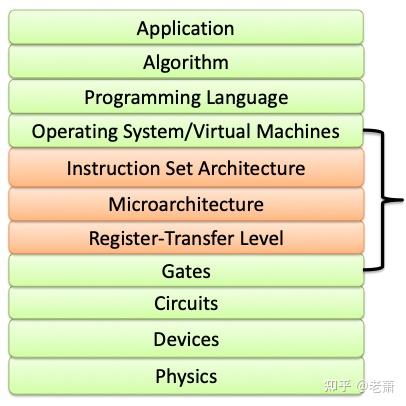
这张图描述了整个计算机系统从上到下的抽象层。首先最顶层的是应用程序(Application),那么应用程序在计算机里是由什么构成的呢?是由它的下一层级,算法(Algorithm)构成的。算法也依赖于所实现它的编程语言(Programming Language),然而编程语言也需要操作系统(Operating System)的支持才能正确工作。那什么东西支持操作系统呢?再往下一层就是我们今天的主角:指令集架构(Instruction Set Architecture, 以下简称 ISA)。
从 ISA 开始往下,都是和硬件电路相关的内容了,所以我们可以得出一个基本的定义:指令集架构是一个能为电路硬件翻译应用程序的一层抽象层。它能够为操作系统制定很多规则和约束,也能让编程者不用操心具体的电路结构,转而在这一抽象的、高级的、定义很多规则的层面编写程序,比如:
- 这个计算机架构里有多少个寄存器(Register)?
- 我能进行哪些运算操作?(有哪些指令?ADD,SUB,MUL等等)
- 如果遇到异常或者中断该怎么办?
- 数据可以有哪些类型?最多有几个字节?
- 等…
ISA 在编译器编写者(CPU软件)和处理器设计人员(CPU硬件)之间提供了一个抽象层:
- 处理器设计者:依据 ISA 来设计处理器;
处理器使用者(如:写编译器的牛*程序员):依据 ISA 就知道 CPU 选用的指令集,就知道自己可以使用哪些指令以及遵循哪些规范。 - 定义处理器上的软件如何构建,这是 ISA 的最重要内涵,现代处理器都是支持高级语言编程、操作系统等等特性,ISA 要定义出指令集内的指令是如何支撑起 C 语言里堆栈、过程调用,操作系统里异常、中断,多媒体平台里数字图像处理、3D 加速等等。
x86 ISA 现在是 Intel 和 AMD 共同拥有,也就是说如果你要开新的 x86 cpu 公司你必须向这两者付版权费用,而且必须两者都同意你才能获得完整的 ISA,如果你只获得一部分不完整的 ISA,那就和完全没拿到 ISA 一样。ISA 在 cpu 里面,就像是字典,用厨房的比喻就是菜谱,菜谱定义了你这个厨房会做什么菜,这个菜做出来是什么样什么味道,那么顾客在这家连锁店的任何一间都能叫到相同的菜,吃到相同的味道。
ARM ISA 当然是 ARM 公司所有的,当时 ARM 公司是定菜单的,并且给出试菜的人,说你们每家店都要做出这个味才算 ARM。而做店的则是不同的公司,像qualcomn 啦,他们中间喜欢怎么做菜是他们的自由,但是必须会那几道菜,必须做出这个味。
提示
- 常见的一个误解的答案:指令集并不存储于CPU中,应该这样说:CPU本身是指令集 (结构) 的一个实现/实例;
- 一个 ISA 可能包含多个指令集;
二、指令集架构 vs 微架构
指令集架构(ISA)和微架构(Microarchitecture)很多时候会被人们混淆。其实微架构就是对 ISA 的一种实现。
综合而言,微架构是指令集架构的一种实现方式,不同的处理器有着不一样的微架构。如果你是 RTL 设计工程师或者验证工程师,你就会拿到处理器的指令集架构的手册,然后根据这个手册来设计或者验证芯片的微架构。
提高 CPU 性能的一个关键方向是如何提高指令级的细粒度并行。目前指令级细粒度并行性的一些方法有:
- 流水线:流水线已经普遍应用于处理器中,通过改进单个流水线的实现,几乎无法再获得更多的收益。
- 多处理器:使用多个处理器仅对有限的应用程序能够起到提高性能的效果。
- 超标量体系结构:超标量架构可以提高所有类型程序的性能。超标量体系结构意味着一次能够完成多个指令的执行
- 每条指令完成多个独立操作:即超长指令字架构(Very Long Instruction Word – VLIW)。

VLIW
市面上多数的 DSP 都是采取 VLIW 指令集(超长指令字),一次发一个指令包,指令包包含多个 slot(指令槽),相当于一次发射多条指令,实现指令级的并行 ILP;DSP 在微架构上的一个优化,就是通过增加指令包的 slot 数量,比如从 4 个增加到 5 个,提高 IPC;
与多发射CPU不一样的是,所有的指令打包都是由编译器完成,因此指令吞吐量很依赖于编译器的优化;
如果遇到前后指令相关依赖的情况,就不能把这些指令放到一个指令包中,这种情况下指令包的指令不是满载的;
许多厂商为了提高 IPC,会对这种情况做相应的优化。
VLIW 指令架构优缺点
优点:
- 不需要动态调度硬件,简化硬件电路
- 不需要在 VLIW 指令中进行依赖项检查,简单的指令多发射硬件
- 取指后分发到不同能单元,不需要进行指令对齐/分配 简化硬件电路
缺点:
- 编译器需要找到 N 个独立的操作
- 如果无法找到,需要在一个 VLIW 指令中插入 NOP,降低并行性,增加代码大小
- 当执行宽度 (N)、指令延迟、功能单元改变时需要重新编译(超标量架构不需要重新编译)
- 同步执行会导致独立操作停止
- 在延迟时间最长的指令完成之前,任何指令都不能执行
三、 指令集分类
指令集架构中最重要的就是所包含的指令(Instructions),一个架构中可能包含成百上千的指令,但它们大致可以被分为一下几类:
- 数据流转移:Load
- 算术逻辑(利用到算术逻辑单元 ALU,arithmetic and logic unit 指令):ADD、SUB、MUL
- 控制流转移:JR(JUMP)、JAL(Jump and Link)、BEQ(Branch if Equal)
- 浮点运算:ADD.D、SUB.S、MUL.D
- 多媒体运算:ADD.PS、SUB.PS
- 字符串运算:REP MOVSB(in x86)
精简指令集RISC【educed instruction set computer】
复杂指令集CISC【complex instruction set computer】
四、 寻址模式
寻址方式就是处理器根据指令中给出的地址信息来寻找有效地址的方式,是确定本条指令的数据地址以及下一条要执行的指令地址的方法。
寻址模式(Addressing Mode)定义了一个指令按照那种方式去寻找想要的数据,其中定义了寄存器和相应的内存位置。
指令寻址的方式包括两部分:
指令的寻址
这里的指令寻址指的是具体的操作码上发出的指令。是 狭义上的指令寻址。数据的寻址
可以理解为地址码上操作数的地址寻址

4.1 指令寻址
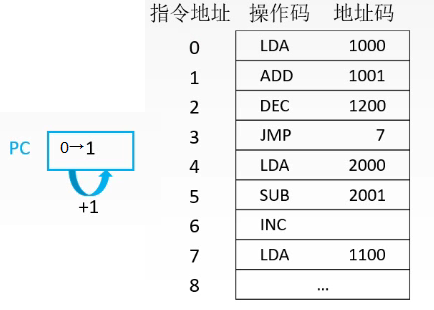
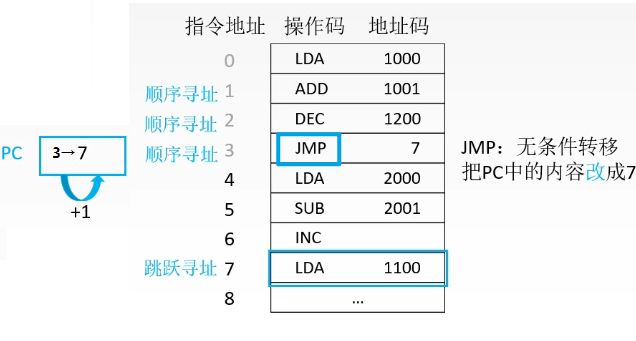
上述即为指令寻址的两种方式:
- 顺序寻址
- 跳转寻址
4.2 数据寻址
通过 顺序寻址或者跳转寻址 取到操作码知道要做什么操作后,我们要拿着地址码去找处理对象了。这里地址码寻址操作对象的寻址方式也是很丰富的简单看个图感受一下:
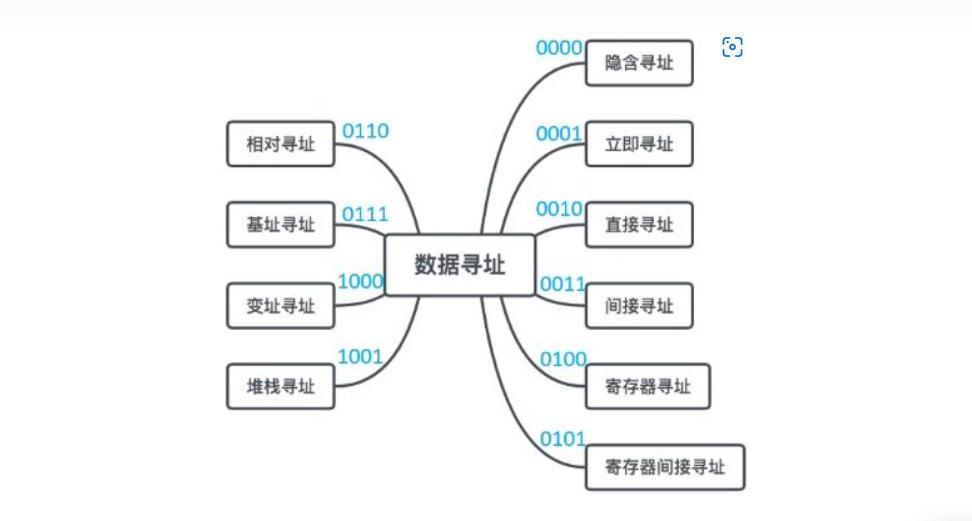
地址码其实分为两部分 —— 寻址特征 + 形式地址:

- 寻址特征存的就是每个寻址方式上的蓝色小标,表示一种方式。
- 形式地址不是直接对应到存储器中的地址,而是需要根据 寻址特征的要求 转换为对应到存储器的地址 。
所以我们把通过 寻址特征和形式地址求出来的真正对应到存储器的地址称之为有效地址。
1. 立即寻址
方式:把我们实际要操作的数,直接存放在形式地址中。立即寻址是获取操作数最快的方式
eg:假如我们要直接操作的数为 3,那么我们可以用一条一地址指令这么设置:

直接把 3 的补码写在形式地址中
- 寻址特征为#,代表立即寻址的意思。
- 形式地址 写的是操作数 3 的补码(011)。
立即寻址主要执行取指令访存1次,不需要执行指令访存,一共访存1次。
立即数:立即寻址方式的目的就是将操作数紧跟在操作码后面,与操作码一起放在指令代码段中,在程序运行时,程序直接调用该操作数,而不需要到其他地址单元中去取相应的操作数,上述的写在指令中的操作数也称作立即数。
2. 直接寻址
直接寻址指令中的地址码字段给的是 操作数的有效位置,我们可以根据这个有效位置直接去内存中寻找操作数。指令中在操作码字段后面的部分是操作数的地址
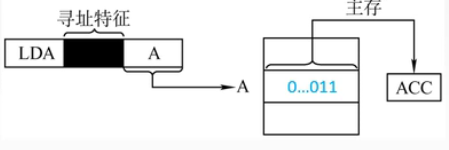

与立即寻址相比:直接寻址主要执行取指令访存1次,还有执行指令访存1次,一共访存2次。
直接寻址和立即寻址的区别
立即寻址:是把一个“常数”送到指定位置。
直接寻址:是把一个“变量”送到指定位置。
3. 间接寻址
指令中给出的地址是操作数地址的地址。
4. 寄存器寻址
指定的寄存器中存放着操作数本身。
5. 寄存器间接寻址
指定的寄存器中存放的不是操作数,而是操作数的地址。
五、 指令编码
对于指令编码(Instruction Encoding),或者说是指令的组成,每个架构的不尽相同。从长度上,可以分为三类:
固定长度指令(Fixed-Length Instruction)
每个指令的长度都一样,好处是解码非常的方便简易。一些 精简指令集(RISC) 的架构,比如 MIPS、ARM、RISC-V、PowerPC就在使用这种模式。
可变化长度指令(Variable-Length Instruction)
每个指令都有自己特定的长度,这样设计的好处是可以压缩缓存器和内存的空间,因为很早之前存储器的容量都很小,很珍贵,所以 可变化长度指令 是最先发展起来的。复杂指令集就是这一阵营的代表:x86(最短 1B,最长可达 17B)、IBM 360、Motorola 68k 等。
压缩型指令(Compressed Instructions)
一般这种指令的长度都非常短(16-Bit),目的都是减少编译后的代码量。代表有 MIPS16、ARM THUMB 等。
还有一种特殊的架构:超长指令集(Very Long Instruction Word,VLIW)是由英特尔和惠普共同在21世纪初提出的一种用于改善工作站性能的新型架构,里面的每条 指令束(Instruction Bundle)是由四条或者更多的普通指令集合在一起而形成的。由于技术和时代原因,最后悄然退场。代表作:IA-64 / Intel Itanium (英特尔安腾处理器)。
参考文献
[1] 关于寻址方式一篇就够了
[2] 如何快速判断立即数
[3] Computer Architecture —— ISA 指令集架构介绍 (一):为什么需要 ISA
[4] Computer Architecture —— ISA 指令集架构介绍 (二):四大特性(完结)
[5] What Is an Instruction Set Architecture?
[6] 科普向 ISA,cpu架构原理
[7] XTENSA处理器介绍
[8] 𝙓𝙩𝙚𝙣𝙨𝙖 基础
[9] HIFI3 DSP芯片技术摘要