CS50 | Week 2 Arrays & Sorts
Last updated on April 30, 2023 am
提示:在此只是将零散的、个人化的知识点记录下来,完整笔记查看官方 Notes 即可。
零散知识点
CPU 只懂得低级别的汇编语言
C language → assembly language → machine language (zeros and ones)
Compiling 包含以下过程:
preprocessing: 预处理,包括查看以
#开头的行,如#include,然后再看其他所有的行; ↓
compiling: 将我们用C语言写的源代码转换为汇编代码;
↓
assembling: 将汇编代码转换为二进制的代码(0和1);
↓
linking: 链接到以前编译的库里面的内容。如:
cs50.c。调试(Debugging)是发现和修复错误的过程。
可以使用一些计数、赋值的
printf来查验代码的错误,最后再删除即可。也就是说如果存在疑问,就在这行或次行加上 printf,来打印出变量中的字符串就可以查出问题所在。注意代码的风格和美观。
CS50 常用的三个工具:
help50: 用于解释你不理解的报错信息;help50 make buggyprintf: 当程序出现bug无法正常运行,用printf检查;printf("i is %i\n", i)style50: 代码格式检查。style50 make buggy2
RAM(Radom Access Memory)是比较短暂的,文件和应用放在 RAM 中会更加高效。
const int COUNT = 3;Encryption:
- 明文(plaintext )+密钥(key,a kind of algorithm)→ 【Black box】 → 密文(ciphertext)
关于返回值:当不设置返回值时,main 自动返回 0。当程序变得复杂时,返回值变得非常有用,因为可以查看程序是否有错。e.g. 404 error,system error 29.
数据类型(Data Types)
In C, we have different types of variables we can use for storing data:
- bool 1 byte
- char 1 byte
- int 4 bytes
- float 4 bytes
- long 8 bytes
- double 8 bytes
- string ? bytes
数组(Arrays)
1 | |
- 数组是连续储存的。在内存中,我们的数组现在是这样存储的,其中每个值占用的不是一个而是四个字节:

你必须把数组长度告诉所有使用他的人,因为它没有
length的属性。e.g.int socres[N];数组像美国高中学校里的大柜子,并且电脑一次只能打开一个柜子来看。
字符串(Strings)
字符串其实只是字符的数组。如果我们有一个字符串s,每个字符都可以用
s[0]、s[1]来访问,以此类推。而事实证明,一个字符串的结尾有一个特殊的字符,’/0’,或者说是一个所有位都设置为0的字节,这个字符被称为空字符,或者说空终止字符。所以我们实际上需要四个字节来存储我们的字符串 “HI!”:
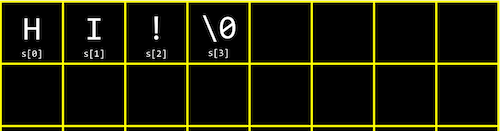
- 现在让我们看看数组中的四个字符串可能是什么样子:
1 | |
- 我们可以将
names中的第一个值打印成一个字符串,或者我们可以得到第一个字符串,并再次使用[]得到该字符串中的每一个字符。(我们可以把它看作是(names[0])[0],尽管我们不需要括号。) - 虽然我们知道第一个名字有四个字符,但
printf可能使用了一个循环来查看字符串中的每一个字符,每次打印一个,直到到达标志着字符串结束的空字符。而事实上,我们可以将names[0][4]作为int与%i一起打印,看到的是一个0被打印出来。 - 我们可以在记忆中直观地看到每个字符都有自己的标签:

比较经典的小写字母变成大写字母的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22#include <cs50.h>
#include <stdio.h>
#include <string.h>
int main(void)
{
string s = get_string("Before: ");
printf("After: ");
for (int i = 0, n = strlen(s); i < n; i++)
{
if (s[i] >= 'a' && s[i] <= 'z')
{
//在ASCII码中,小写字母比大写字母大32,a = 97,A = 65
printf("%c", s[i] - 32);
}
else
{
printf("%c", s[i]);
}
}
printf("\n");
}可以使用
strlen(name)来得到字符串长度。e.g. strlen(“Erenlu”), 结果就是 6。- 要记得在顶部先引用
#include <string.h>才能使用
- 要记得在顶部先引用
排序(Sort)
时时刻刻我们都应该问算法是否高效。
冒泡排序(Bubble sort)
一种比较排序法。两两对比,将更小的交换到左边。每次解决一个小问题,但需要反反复复地去做。
伪代码(pseudocode):
1
2
3
4repeat until no swaps
for i from n-2 //倒数第二个,避免倒数第一个右边没有可比的
if i'th and i+1'th elements out of order //判断是否排序混乱
swap them
- 假如有 8 个数字,由以下步骤进行排序:
- 第一次:比较 7 次,[0,1] [1,2] [2,3]….[6,7]
- 第二次:比较 6 次,,[0,1]….[6,7],(最后一个已经排序好了)
- ….
- 第七次:比较1 次,[0,1] (后面六个都排序好了)
- 优点:最右边已经确定,每次比较都可以少一个。
选择排序(Selection sort)
每一次都选择剩下中数字最小的人,丢到左边去交换,这样每一次排序后就不用管之前的情况。所以剩下的工作会原来越少。
伪代码:
1
2
3For i from 0 to n–1
Find smallest item between i'th item and last item
Swap smallest item with i'th item进行的次数为: (n - 1) + (n - 2) + … + 1 = n(n - 1) / 2 = n² / 2 - n / 2
假如有 8 个数字,由以下步骤进行排序:
- 第一次:找出最小的数字,把 1 交换到最左边
第二次:找出剩下最小的数字,把 2 交换到左边
…
第七次:找出剩下最小的数字,把 7 交换到左边
- 第一次:找出最小的数字,把 1 交换到最左边
优点:最左边已经确定,每次比较都可以少一个人 缺点:每次都要搜寻一遍最小数,即使一开始顺序就是对的。
归并排序(Merge sort)
不断地进行二等分,直到最小单位再开始进行比较,再最后进行合并比较。
伪代码:
1
2
3
4
5
6If only one item
Return
Else
Sort left half of items
Sort right half of items
Merge sorted halves假如有 8 个数字,由以下步骤进行排序:
先一直二等分成最小数字,再进行合併
第一次:合併成 4 组 2 个数字
第二次:合併成 2 组 4 个数字
第三次:合併成 1 组 8 个数字
优点:移动的次数比泡沫跟选择更有效率,每个数字只移动了 3 次,8 * 3 共 24 次 缺点:需要用到额外记忆体。
算法的时间复杂度
由最高次幂决定。

时间复杂度由最差 → 最优
由以下这张 gif 可以看出三种排序法明显的差别,以时间复杂度来说,Merge 优于 Bubble 优于 Selection:

同时运行的具有大量输入的排序算法的 最终可视化 视频。